Criando uma Rede Neural do Zero com Python
Usando apenas matemática e o Numpy. Sem Tensorflow ou Pytorch!
Acesse o código completo: https://github.com/Ga0512/NN_only_numpy/tree/main

Existe um jeito bem simples de criar a sua própria rede neural com python, sem precisar recorrer recorrer a frameworks como TensorFlow ou PyTorch.
Se você achar confuso demais, talvez seja melhor dar um passo para atrás e começar pela parte teórica.
Obtendo a Base de Dados
Vou estar usando a base de dados de dígitos manuscritos MNIST, muito usado em aplicações de redes neurais, você pode fazer download do csv por aqui: https://www.kaggle.com/competitions/digit-recognizer/data?select=train.csv
Carregando e preparando os dados
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
data = pd.read_csv('train.csv')
data = np.array(data)
m, n = data.shape
np.random.shuffle(data)
data_dev = data[0:1000].T
Y_dev = data_dev[0]
X_dev = data_dev[1:n]
X_dev = X_dev / 255.
data_train = data[1000:m].T
Y_train = data_train[0]
X_train = data_train[1:n]
X_train = X_train / 255.
_,m_train = X_train.shape
Importamos as bibliotecas NumPy, Pandas e Matplotlib, e carregamos a base de dados. O DataFrame é convertido em um array NumPy para facilitar a manipulação. Os dados são embaralhados para garantir distribuição aleatória. Separamos os primeiros 1000 exemplos como conjunto de validação, normalizando as características. Os exemplos restantes formam o conjunto de treinamento, também com características normalizadas. A variável m_train armazena o número de exemplos de treinamento.
Parâmetros da rede neural
def init_params():
W1 = np.random.rand(10, 784) - 0.5
b1 = np.random.rand(10, 1) - 0.5
W2 = np.random.rand(10, 10) - 0.5
b2 = np.random.rand(10, 1) - 0.5
return W1, b1, W2, b2
def ReLU(Z):
return np.maximum(Z, 0)
def softmax(Z):
A = np.exp(Z) / sum(np.exp(Z))
return A
def forward_prop(W1, b1, W2, b2, X):
Z1 = W1.dot(X) + b1
A1 = ReLU(Z1)
Z2 = W2.dot(A1) + b2
A2 = softmax(Z2)
return Z1, A1, Z2, A2
def ReLU_deriv(Z):
return Z > 0
def one_hot(Y):
one_hot_Y = np.zeros((Y.size, Y.max() + 1))
one_hot_Y[np.arange(Y.size), Y] = 1
one_hot_Y = one_hot_Y.T
return one_hot_Y
def backward_prop(Z1, A1, Z2, A2, W1, W2, X, Y):
one_hot_Y = one_hot(Y)
dZ2 = A2 - one_hot_Y
dW2 = 1 / m * dZ2.dot(A1.T)
db2 = 1 / m * np.sum(dZ2)
dZ1 = W2.T.dot(dZ2) * ReLU_deriv(Z1)
dW1 = 1 / m * dZ1.dot(X.T)
db1 = 1 / m * np.sum(dZ1)
return dW1, db1, dW2, db2
def update_params(W1, b1, W2, b2, dW1, db1, dW2, db2, alpha):
W1 = W1 - alpha * dW1
b1 = b1 - alpha * db1
W2 = W2 - alpha * dW2
b2 = b2 - alpha * db2
return W1, b1, W2, b2
def get_predictions(A2):
return np.argmax(A2, 0)
def get_accuracy(predictions, Y):
print(predictions, Y)
return np.sum(predictions == Y) / Y.size
def gradient_descent(X, Y, alpha, iterations):
W1, b1, W2, b2 = init_params()
for i in range(iterations):
Z1, A1, Z2, A2 = forward_prop(W1, b1, W2, b2, X)
dW1, db1, dW2, db2 = backward_prop(Z1, A1, Z2, A2, W1, W2, X, Y)
W1, b1, W2, b2 = update_params(W1, b1, W2, b2, dW1, db1, dW2, db2, alpha)
if i % 10 == 0:
print("Iteration: ", i)
predictions = get_predictions(A2)
print(get_accuracy(predictions, Y))
return W1, b1, W2, b2
Parece confuso, e é, mas aqui definimos os parâmetros da rede neural
Inicialização dos parâmetros:
A função init_params inicializa os pesos e bias das duas camadas da rede neural com valores aleatórios entre -0.5 e 0.5.
Função ReLU: A função ReLU (Rectified Linear Unit) retorna o valor de entrada se positivo, e 0 se negativo, introduzindo não-linearidade na rede.
Função softmax: A função softmax converte um vetor de entrada em probabilidades, normalizando os valores para que somem 1, útil na camada de saída de classificadores.
Propagação para frente:
A função forward_prop calcula as ativações das camadas aplicando pesos, bias, ReLU e softmax, retornando valores intermediários e finais.
Derivada da ReLU:
A função ReLU_deriv calcula a derivada da ReLU, essencial para o ajuste de pesos na retropropagação.
Codificação one-hot:
A função one_hot transforma os rótulos Y em uma matriz one-hot, facilitando o cálculo do erro na retropropagação.
Propagação para trás:
A função backward_prop calcula os gradientes dos pesos e bias com base no erro das previsões, utilizando as funções derivadas e one-hot.
Atualização dos parâmetros:
A função update_params ajusta os pesos e bias subtraindo o produto da taxa de aprendizado pelos gradientes calculados.
Obtenção das previsões:
A função get_predictions retorna as previsões da rede, escolhendo a classe com maior probabilidade na ativação final.
Cálculo da precisão:
A função get_accuracy calcula e imprime a porcentagem de previsões corretas comparando-as com os rótulos reais Y.
Gradiente descendente:
A função gradient_descent treina a rede neural iterativamente, realizando propagação para frente e para trás, atualizando os parâmetros e imprimindo a precisão a cada 10 iterações, retornando os parâmetros ajustados.
Também definimos que a nossa rede neural possui 784 neurônios na camada de entrada (28x28 pixels da imagem) apenas para passar para as próximas camadas, que são duas: a camada oculta com 10 neurônios e função de ativação ReLU e a de saída com 10 neurônios também (um para cada classe de dígitos, ou seja, 0, 1, 2, 3… 9) com função de ativação softmax.
Treinamento
W1, b1, W2, b2 = gradient_descent(X_train, Y_train, 0.10, 500)
Esse código executa o treinamento da rede neural utilizando a função gradient_descent com os dados de treinamento, uma taxa de aprendizado de 0.10 e 500 iterações (épocas).
E no meu caso, o meu accuracy foi de 0.8370731707317073, ou seja, um precisão de cerca de 83% no treinamento.
Validação
def make_predictions(X, W1, b1, W2, b2):
Z1, A1, Z2, A2 = forward_prop(W1, b1, W2, b2, X)
predictions = get_predictions(A2)
print(Z1.shape, A1.shape, Z2.shape, A2.shape)
return predictions
def test_prediction(index, W1, b1, W2, b2):
current_image = X_train[:, index, None]
prediction = make_predictions(X_train[:, index, None], W1, b1, W2, b2)
label = Y_train[index]
print("Prediction: ", prediction)
print("Label: ", label)
current_image = current_image.reshape((28, 28)) * 255
plt.gray()
plt.imshow(current_image, interpolation='nearest')
plt.show()
test_prediction(1, W1, b1, W2, b2)
Prediction: [0] Label: 0
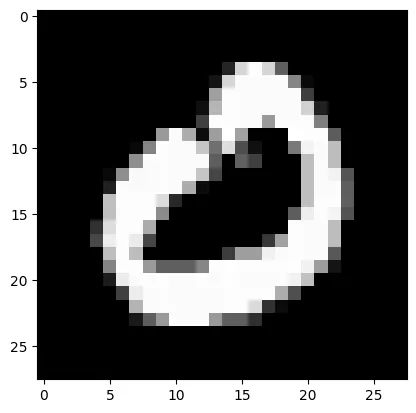
Função make_predictions: Realiza previsões usando os parâmetros da rede neural e os dados de entrada fornecidos. Executa a propagação para frente, calcula as ativações finais e retorna as previsões.
Função test_prediction: Testa a previsão do modelo em uma única amostra de dados de treinamento, especificada pelo índice fornecido. Chama make_predictions para obter a previsão da rede neural, imprime a previsão e o rótulo verdadeiro, e exibe a imagem correspondente usando Matplotlib para avaliação visual e manual da precisão do modelo.
E como vocês podem ver, o modelo acertou! A imagem é um digito “0” e a rede neural previu corretamente.
Acesse o código completo: https://github.com/Ga0512/NN_only_numpy/tree/main
Koé, me segue no LinkedIn também: Gabriel M. Cicotoste.
Achei interessante demais. Sobre dar um passo atrás, o que você sugeriria estudar/pesquisar para ter base suficiente e me aventurar na criação dessa rede neural?
oloko, achei brabo dms. Vou até tirar um tempo pra estudar rede neural com pythonzada.
que viage viu veio, mas que daora mano, vou estudar mais python pra alcançar isso