Visão Geral sobre o HTTP
O protocolo HTTP está intrínsicamente ligado a Web, e entender o funcionamento da Web é essencial para qualquer pessoa que queira se aventurar na área da tecnologia.
A web é sobre uma comunicação entre dois computadores. Esses dois computadores são comumente chamados cliente e servidor.
- O cliente geralmente é um navegador, mas também pode ser um celular ou outro tipo de dispositivo ou programa.
- O servidor é um computador que guarda dados, e responde aos pedidos do navegador. Atualmente, muitos servidores estão na nuvem, mas também podem ser computadores locais.
Essa comunicação é controlada por um protocolo, que é um conjunto de regras que governa sobre a sintaxe, semântica e sinconização da comunicação. Um protocolo padroniza a comunicação possibilitando que diferentes dispositivos (como um navegador, celular ou até uma geladeira inteligente) se comuniquem e troquem dados e informações.
O HTTP (HyperText Transfer Protocol) é o protocolo convencionado para a utilização na Web. Ele foi criado em 1989, por Tim Berners-Lee, com o objetivo de compartilhar os documentos e informações entre os físicos de sua faculdade.
O HTTP funciona com base em dois conceitos básicos: requisição (request) e resposta (response). Na requisição, estão as informações que o cliente (geralmente, o navegador) envia para o servidor. Enquanto na resposta, estão os dados de resposta do servidor.
Existem alguns tipos de métodos dentro dessa comunicação, para que se possa entender a ação que o navegador quer executar. Alguns exemplos:
- GET: pede os dados que estão armazenados no servidor. Exemplo: quando acessamos um vídeo do YouTube, requisitamos o vídeo presente no banco de dados de algum servidor do YouTube. Estamos fazendo um GET, utilizando URL, que está especificando o pedido de acordo com as regras definidas pelos desenvolvedores do YouTube.
- POST: armazena algum dado no servidor. Exemplo: ao criarmos uma conta no Instagram, enviamos nossos dados (e-mail, senha, data de nascimento) para um servidor, que fará a validação e armazenará.
- PUT: cria ou atualiza um recurso.
- DELETE: exclui um recurso.
Esse é um exemplo de um cabeçalho de uma requisição:
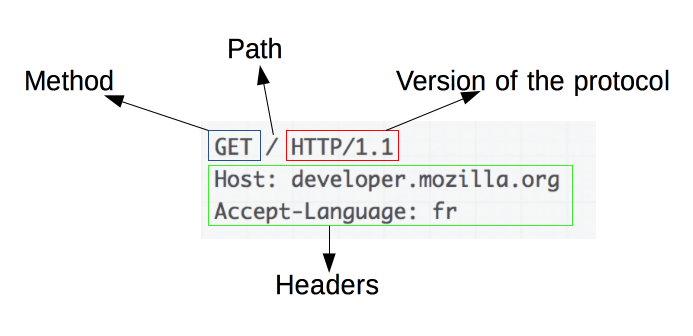
No cabeçalho, existem informações específicas, como o tipo de dado esperado como resposta, a linguagem, o Host. Dá pra encontrar todos as informações que podem entrar em um cabeçalho na documentação da MDN, que é bem completa.
A resposta vem atráves de códigos que representam o status do pedido do cliente:
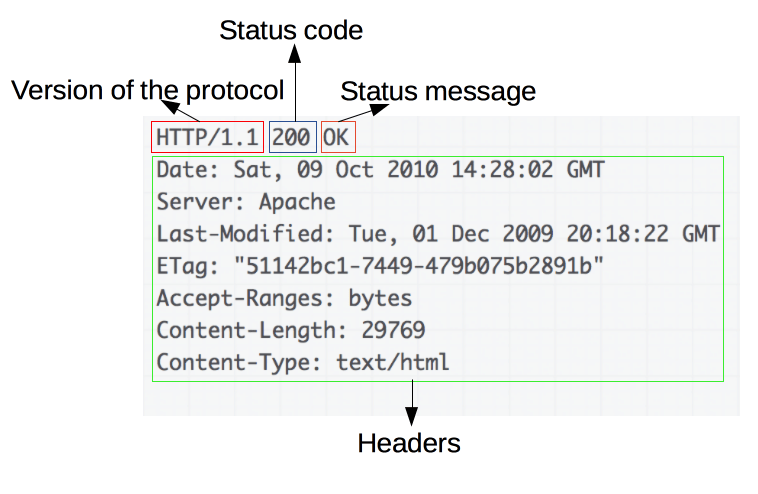
Os códigos são divididos nas seguintes categorias:
- 100-199: Respostas de informação
- 200-299: Respostas de sucesso
- 300-399: Redirecionamentos
- 400-499: Erros do cliente
- 500-599: Erros do servidor
Esse é um dos assuntos que estudei nos últimos dias e que queria compartilhar como forma de fixar o conhecimento e começar a usar mais ativamente o TabNews para conversar sobre tecnologia.
O cliente geralmente é um navegador
Algo pra buscar Google e ChatGPT afora :) : pensando que APIs REST (JSON sobre HTTP) é um modelo bem comum de integração entre sistemas distribuidos, será que a sua afirmação acima é verdadeira?
excelente !!
Show de bola, parabéns por compartilhar um conceito tão fundamental para todos que estão envolvido no meio da tecnologia.
Texto simples e bem explicado. Muito obrigada pela sua contribuição!