[DATA SCIENCE] DAY: 026 - Pré-processamento com Scikit-Learn
🌎 Bom dia, boa tarde e boa noite pessoal, tudo bem?
🛀 Hoje iremos falar sobre Pré-processamento com Scikit-Learn:
Pré-processamento com Scikit-Learn é o processo de preparar os dados para serem utilizados em modelos de aprendizado de máquina antes de iniciar o treinamento. Isso inclui tarefas como limpeza de dados, normalização, transformação e seleção de características. O scikit-learn fornece várias ferramentas para realizar essas tarefas, como transformadores e seletores de recursos, que podem ser facilmente integrados ao fluxo de trabalho de aprendizado de máquina. Significado da web
📝 Obs: Irei utilizar o jupyter notebook para a fácil visualização dos gráficos, mas fique a vontade para escolher outro ambiente de sua preferência. Uma sugestão caso não conheça nenhum, tem o colab do google.
1 - Primeiro, podemos usar a notação as para abreviar o nome das bibliotecas e métodos que vamos importar, vamos aplicar a configuração de visualização de alguns gráficos, ler um arquivo CSV e renomear as colunas:
🔍 Para baixar o arquivo que está sendo usado, clique aqui.
:computer:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import rcParams
from sklearn import preprocessing
%matplotlib inline
rcParams['figure.figsize'] = 5, 4
sns.set_style('whitegrid')
caminho = 'O-caminho-do-seu-arquivo-aqui/mtcars.csv'
carros = pd.read_csv(caminho)
carros.columns = ['nomes','mpg','cyl','disp', 'hp', 'drat', 'wt', 'qsec', 'vs', 'am', 'qtd_marchas', 'carb']
mpg = carros.mpg
📝 Obs: O que esse código faz???
- Importação de bibliotecas: O código importa as bibliotecas pandas, seaborn e matplotlib.pyplot para trabalhar com dados, visualização e plotagem de gráficos. Ele também importa a biblioteca
preprocessingdoscikit-learnpara realizar pré-processamento de dados. - Configuração de visualização: O código configura a visualização dos gráficos usando o matplotlib e o seaborn. Ele também define o tamanho da figura.
- Leitura de dados: O código lê os dados do arquivo csv
mtcars.csvarmazenado no caminho especificado e armazena-os em um dataframe chamado "carros". Ele também renomeia as colunas do dataframe. - Seleção de dados: O código seleciona a coluna
mpgdo dataframecarrose armazena em uma variável chamadampg.
O próximo passo será normalizar e transformar variáveis com
MinMaxScalar()efit_transform():
2 - Para isso, vamos selecionar a coluna mpg do dataframe carros e calcular algumas estatísticas descritivas básicas para essa coluna utilizando o método describe():
:computer:
carros[['mpg']].describe()
Saída do código:
mpg
count 32.000000
mean 20.090625
std 6.026948
min 10.400000
25% 15.425000
50% 19.200000
75% 22.800000
max 33.900000
📝 Obs: O que esse código faz???
- Seleção de coluna: O comando está selecionando a coluna
mpgdo dataframecarrosatravés de seu nome, usando o operador de indexação[]. - Estatísticas geradas: As estatísticas geradas pelo método
describe()incluem informações como a contagem de valores, a média, o desvio padrão, os quartis e os valores mínimo e máximo. Estas estatísticas fornecem uma visão geral dos dados contidos na coluna selecionada.
3 - Agora podemos plotar um gráfico de linha com os dados contidos na variável mpg. O eixo x é indexado automaticamente, e o eixo y é representado pelos valores contidos na variável mpg:
:computer:
plt.plot(mpg)
Gráfico gerado:

📝 Obs: O que esse código faz???
-
Biblioteca Matplotlib: O comando está usando a biblioteca Matplotlib, uma das principais bibliotecas de plotagem de gráficos em Python. Ela fornece uma variedade de ferramentas para criar gráficos de diferentes tipos e formatos.
-
Função plot(): A função
plot()é usada para plotar os dados em forma de linha. Ela é uma das principais funções da biblioteca Matplotlib. -
Dados de entrada: O comando está passando a variável
mpgcomo argumento para a funçãoplot(). Essa variável deve conter os dados que serão usados para plotar o gráfico. -
Plotagem do gráfico: A função
plot()irá plotar um gráfico de linha com os dados contidos na variávelmpg. O eixoxé indexado automaticamente, e o eixoyé representado pelos valores contidos na variávelmpg. -
plt: A função plt é a forma abreviada de
matplotlib.pyplot, que é um módulo da biblioteca matplotlib onde se encontra as funções de plotagem.
4 - Próximo passo é converter os dados contidos na variável mpg em uma matriz com uma única coluna para poder aplicar o pré-processamento do scikit-learn:
:computer:
mpg_mat = mpg.values.reshape(-1,1)
scaled = preprocessing.MinMaxScaler()
scaled_mpg = scaled.fit_transform(mpg_mat)
plt.plot(scaled_mpg)
Gráfico gerado:
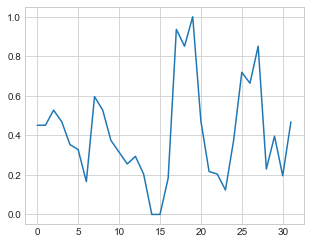
📝 Obs: O que esse código faz???
-
Transformação de formato de dados: A primeira linha está convertendo os dados contidos na variável
mpgem uma matriz com uma única coluna, usando o métodovalues.reshape(-1,1). Isso é necessário para que os dados possam ser usados com a biblioteca de pré-processamento(preprocessing). -
Normalização dos dados: A segunda linha está criando uma instância da classe
MinMaxScalerda biblioteca de pré-processamento(preprocessing)do scikit-learn. A terceira linha está usando o métodofit_transformpara normalizar os dados contidos na matrizmpg_matentre 0 e 1. A normalização é importante para garantir que todas as features tenham o mesmo peso e impacto no modelo. -
Plotagem do gráfico: A quarta linha está usando a biblioteca Matplotlib para plotar um gráfico de linha com os dados normalizados contidos na variável
scaled_mpg. Assim como a função anterior, o eixoxé indexado automaticamente, e o eixoyé representado pelos valores contidos na variávelscaled_mpg.
Vamos utilizar uma pequena diferença em comparação ao código anterior onde a normalização é realizada entre 0 e 1, enquanto que neste código que vamos elaborar a normalização é realizada entre 0 e 10:
:computer:
scaled = preprocessing.MinMaxScaler(feature_range=(0,10))
scaled_mpg = scaled.fit_transform(mpg_mat)
plt.plot(scaled_mpg)
Gráfico gerado:
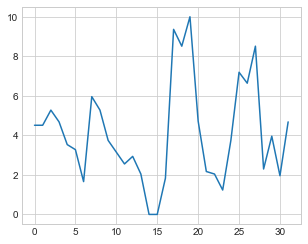
📝 Obs: O que esse código faz???
-
Transformação de formato de dados: A primeira linha está convertendo os dados contidos na variável
mpgem uma matriz com uma única coluna, usando o métodovalues.reshape(-1,1). Isso é necessário para que os dados possam ser usados com a biblioteca de pré-processamento(preprocessing). -
Normalização dos dados: A segunda linha está criando uma instância da classe
MinMaxScalerda biblioteca de pré-processamento (preprocessing) doscikit-learn, e esta vez é passado um parâmetro adicionalfeature_range=(0,10)que está definindo o range de valores da normalização. A terceira linha está usando o métodofit_transformpara normalizar os dados contidos na matrizmpg_matentre 0 e 10. A normalização é importante para garantir que todas as features tenham o mesmo peso e impacto no modelo. -
Plotagem do gráfico: A quarta linha está usando a biblioteca Matplotlib para plotar um gráfico de linha com os dados normalizados contidos na variável
scaled_mpg. Assim como a função anterior, o eixoxé indexado automaticamente, e o eixoyé representado pelos valores contidos na variávelscaled_mpg.
5 - Por último, vamos utilizar o método scale() para padronizar as variáveis:
:computer:
mpg_padronizado = preprocessing.scale(mpg, axis=0, with_mean=False, with_std=False)
plt.plot(mpg_padronizado)
Gráfico gerado:

📝 Obs: O que esse código faz???
- Padronização dos dados: A primeira linha está utilizando o método
scaleda biblioteca de pré-processamento (preprocessing) doscikit-learnpara padronizar os dados contidos na variávelmpg. - O parâmetro
axis=0indica que a padronização deve ser aplicada ao longo das linhas (amostras) e não das colunas (features). - O parâmetro
with_mean=Falseewith_std=Falseindica que a média e desvio padrão dos dados não devem ser utilizados na padronização. - Armazenamento dos dados padronizados: A padronização é armazenada na variável
mpg_padronizado. - Plotagem do gráfico: A terceira linha está usando a biblioteca Matplotlib para plotar um gráfico de linha com os dados padronizados contidos na variável
mpg_padronizado. - Assim como as funções anteriores, o eixo
xé indexado automaticamente, e o eixoyé representado pelos valores contidos na variávelmpg_padronizado. - A Padronização é uma técnica de pré-processamento que transforma as features para que tenham uma distribuição normal com média 0 e desvio padrão 1, é útil para algoritmos de aprendizado de máquina que esperam que as features estejam na mesma escala.
- Diferente da normalização, a padronização não leva em conta o valor máximo e mínimo dos dados, mas sim a distribuição dos dados.
Para finalizar, vamos padronizar os dados contidos na variável mpg e plotar um gráfico de linha com os dados padronizados:
:computer:
mpg_padronizado = preprocessing.scale(mpg)
plt.plot(mpg_padronizado)
Gráfico gerado:
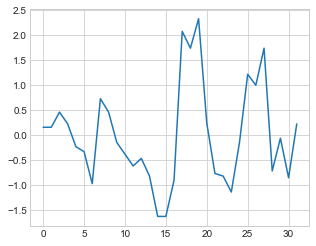
Obs: A padronização é uma técnica de pré-processamento que transforma as features para que tenham uma distribuição normal com média 0 e desvio padrão 1, é útil para algoritmos de aprendizado de máquina que esperam que as features estejam na mesma escala.
🌊 Espero que tenham gostado do conteúdo!
📱💼 Aproveito a oportunidade para deixar meu Linkedin para fazer network com vocês.
🚀 Vejo vocês amanhã, tenham uma ótima semana!

Fala aí onlyDataFans,
Muito legal o post!
Só dá uma olhada nas imagens (de novo 😂) e um GRANDE disclaimer que tem que fazer nessa parte aí.
Antes de aplicar essa técnica, tem que tirar os outliers, depois padronizar e depois normalizar.