[DATA SCIENCE] DAY: 019 - Visualizando Scatter Plots
👨💼 Bom dia, boa tarde e boa noite pessoal, tudo bem?
📊 Hoje iremos aprender como criar e visualizar Box Plots.
Um scatter plot, ou gráfico de dispersão, é um tipo de gráfico usado para mostrar como duas variáveis estão relacionadas. Ele mostra cada par de valores (x, y) como um ponto no plano cartesiano. Scatter plots são úteis para mostrar tendências e relações entre variáveis, como se uma variável aumenta ou diminui com a outra. É uma boa ferramenta para visualizar dados e identificar padrões. Significado da web
1 - Primeiro, podemos usar a notação as para abreviar o nome das bibliotecas que vamos importar e facilitar a escrita de código:
:computer:
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import rcParams
import seaborn as sns
📝 Obs:
- A primeira linha
import pandas as pdimporta a biblioteca pandas para utilizar suas funções para manipular e analisar dados. - A segunda linha
from matplotlib import pyplot as pltimporta o módulo pyplot da biblioteca matplotlib para criar gráficos. - A terceira linha
from matplotlib import rcParamsimporta as configurações de parâmetros padrão da biblioteca matplotlib. - A quarta linha
import seaborn as snsimporta a biblioteca seaborn que fornece uma interface mais fácil para criar gráficos estatísticos atraentes e informativos, e também estende as funcionalidades de matplotlib.
Essas linhas de código preparam as bibliotecas necessárias para serem utilizadas na visualização de dados.
2 - Agora vamos ajustar as configurações de visualização para se adequar ao ambiente do Jupyter Notebook e estabelecer um estilo de gráfico padrão para ser usado ao longo do código:
:computer:
%matplotlib inline
rcParams['figure.figsize'] = 5, 4
sns.set_style('whitegrid')
📝 Obs:
-
%matplotlib inline: Essa linha de código é usada para exibir gráficos dentro do notebook Jupyter. Isso significa que, em vez de abrir uma nova janela para exibir o gráfico, ele será exibido diretamente no notebook. -
rcParams['figure.figsize'] = 5, 4: Essa linha de código define o tamanho da figura como 5x4. Isso significa que a largura será de 5 unidades e a altura será de 4 unidades. -
sns.set_style('whitegrid'): Essa linha de código é parte do seaborn, uma biblioteca de visualização de dados baseada em Matplotlib. Ele define o estilo de grade como branco. Isso adiciona linhas brancas às suas visualizações de dados, o que pode ajudar a tornar os gráficos mais legíveis e fáceis de interpretar.
3 - Agora após as configurações, iremos gerar dois gráficos scatter plots para visualizar a distribuição dos dados de formas diferentes:
:computer:
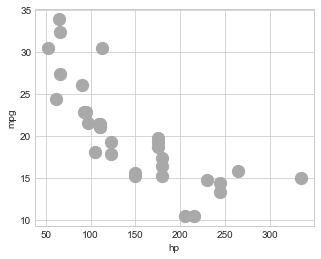
carros.plot(kind='scatter', x='hp', y='mpg', c=['darkgray'], s=150)
📝 Obs: O que esse código faz???
- O código está criando um gráfico de dispersão usando os dados
carros. - O eixo x representa o cavalo de potência
hpdos carros nos dados. - O eixo y representa o consumo de combustível em milhas por galão
mpgdos carros nos dados. - A cor dos pontos no gráfico é
cinza escuro(c=['darkgray']). - O tamanho dos pontos no gráfico é 150
(s=150).
Gráfico gerado:
Agora utilizando vamos criar um gráfico de dispersão com uma linha de regressão linear usando a biblioteca seaborn:
:computer:
sns.regplot(x='hp', y='mpg', data=carros, scatter=True)
📝 Obs: O que esse código faz???
- O código está criando um gráfico de dispersão com uma linha de regressão linear usando a biblioteca seaborn.
- Os dados utilizados são do
carros. - O eixo x representa o cavalo de potência
hpdos carros nos dados. - O eixo y representa o consumo de combustível em milhas por galão
mpgdos carros nos dados. - O parâmetro
scatter=Trueindica que é desenhado um gráfico de dispersão juntamente com a linha de regressão.
Gráfico gerado:
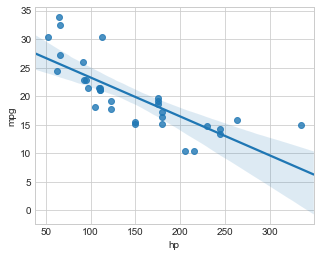
Obs:
Regressão linear é um método estatístico utilizado para encontrar a relação entre uma variável dependente (y) e uma ou mais variáveis independentes (x). Ele tenta encontrar uma equação matemática que melhor se ajusta aos dados fornecidos, para prever a variação da variável dependente (y) com base na(s) variável(is) independente(s) (x). É chamado de "linear" porque a relação entre as variáveis é representada por uma reta.
🌊 Espero que tenham gostado do conteúdo! Caso queiram um assunto mais detalhado sobre regressão linear, comentem aí!
🚀 Vejo vocês amanhã, tenham uma ótima semana!

Que legal! Essa "mancha" é gerada pelo próprio sns? É possível obter o valor dela?. Eu conheço como alpha e entendo como a margem de erro, é isso mesmo?