Problema da Ordem Definida Pelo Usuário
Introdução
Você já se deparou com o seguinte problema?
Você tem uma lista de conteúdos, e o usuário pode alterar a ordem dessa lista à vontade. Além disso, essa ordem precisa ser mantida para o usuário na próxima vez que ele acessar a lista.
Esse problema, que à primeira vista parece simples, esconde uma complexidade considerável. O desafio principal é como realizar essas mudanças de forma eficiente, minimizando o número de alterações no banco de dados.
Neste post quero explorar algumas soluções para esse problema usando SQL e PostgreSQL.
Modelagens
Simples
Uma abordagem inicial seria modelar a lista usando uma coluna inteira chamada position, que determina a posição de cada item na lista.
CREATE TABLE card (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
position INTEGER UNIQUE NOT NULL
);
A inserção de elementos nessa estrutura é bastante simples:
INSERT INTO card (content)
VALUES ('content1'),
('content2'),
('content3'),
('content4');
SELECT * FROM card ORDER BY position ASC;
| id | content | position |
|---|---|---|
| 1 | content1 | 1 |
| 2 | content2 | 2 |
| 3 | content3 | 3 |
| 4 | content4 | 4 |
Isso nos dá uma lista ordenada pelos valores de position.
No entanto, a dificuldade surge quando o usuário decide reordenar os itens. Suponha que o usuário deseje mover o item com position = 3 para a primeira posição. Com essa modelagem, você precisaria:
- Atualizar o item movido para
position = 1 - Incrementar a posição de todos os outros itens que foram deslocados.
UPDATE card
SET position = position + 1
WHERE position >= 1 AND position < 3;
UPDATE card
SET position = 1
WHERE content = 'content3';
Esse processo envolve múltiplas operações de atualização, o que pode ser ineficiente, especialmente em listas longas.
Posição Decimal
Agora, e se trocássemos o INTEGER por FLOAT para trabalhar com valores decimais? Isso permitiria inserir novos elementos na lista calculando a média entre duas posições (position = (i+j)/2), facilitando a reordenação sem precisar atualizar todas as posições subsequentes.
CREATE TABLE card (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
position FLOAT UNIQUE NOT NULL
);
INSERT INTO card (content, position)
VALUES ('content1', 1.0),
('content2', 2.0),
('content3', 3.0),
('content4', 4.0);
Se for necessário mover o conteúdo 3 para a primeira posição, basta aplicar a média:
UPDATE card
SET position = (0 + 1.0)/2
WHERE content = 'content3';
A princípio, essa parece uma solução eficiente. No entanto, números de ponto flutuante têm uma precisão limitada, o que pode gerar problemas com mudanças sucessivas ao longo do tempo, causando erros de arredondamento e perda de precisão.
Frações Verdadeiras
Tanto a solução usando INTEGER quanto FLOAT têm limitações significativas, especialmente no manejo de posições médias e atualizações consecutivas. Uma abordagem alternativa e mais robusta seria o uso de frações verdadeiras.
Embora o PostgreSQL não ofereça suporte nativo para frações, a extensão pg_rational, criada por begriffs, permite trabalhar com números racionais. Esta extensão converte valores decimais em frações verdadeiras, evitando problemas de precisão. O código pode ser encontrado no GitHub.
A ideia é que as frações não negativas podem ser representadas como uma árvore binária, especificamente a Árvore de Stern–Brocot. Esta árvore permite encontrar frações dentro de limites definidos até atingir o nó desejado, proporcionando uma forma eficiente de reordenar elementos.
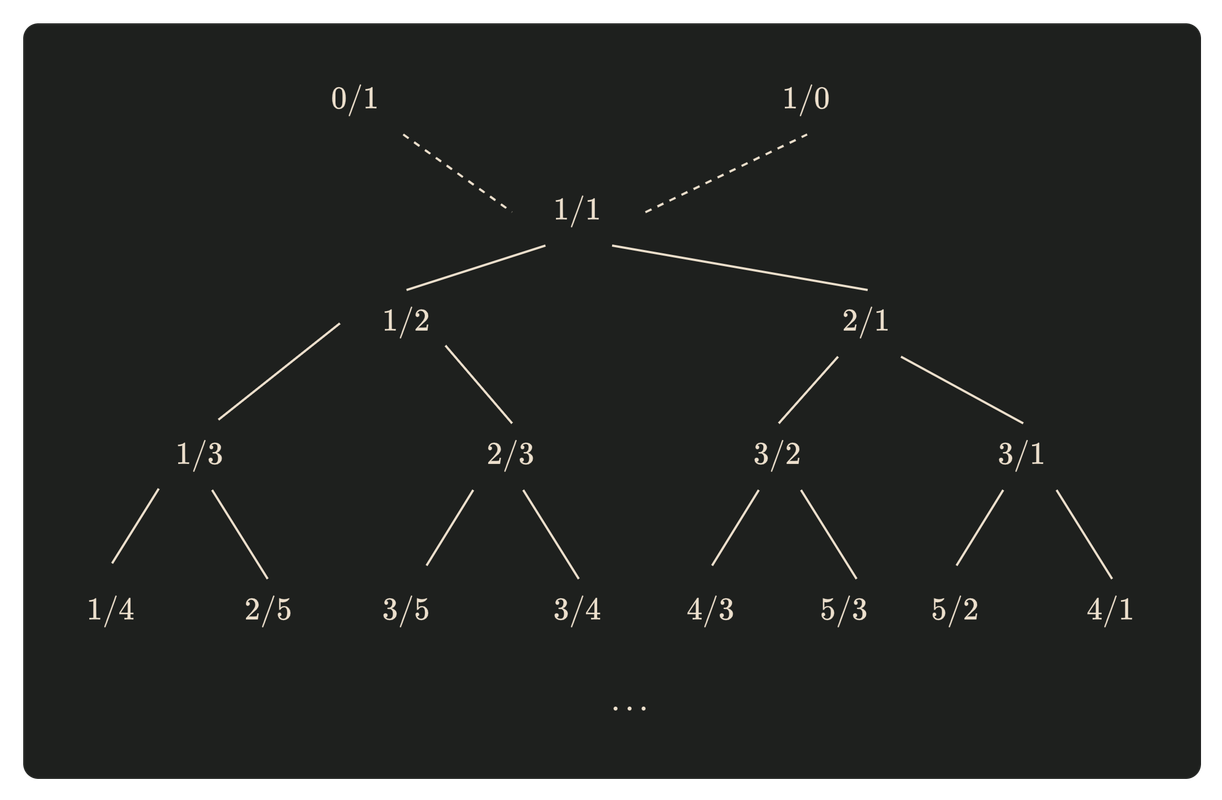
Esse método foi um dos melhores que encontrei para manipular a ordem dos itens em listas, mas por não ser uma funcionalidade padrão do PostgreSQL, pode limitar seu uso. No entanto, para quem busca uma solução avançada, vale a pena explorar. Recomendo a leitura da publicação do autor sobre esse método: User-defined Order in SQL.
Árvore Binária
Por fim, uma solução interessante que utiliza uma variação da Árvore de Stern–Brocot, mas implementada de forma nativa no PostgreSQL, é o uso de uma árvore binária de bits. Esta abordagem se baseia em representar posições na lista como sequências binárias, permitindo a inserção de novos elementos entre dois valores adjacentes sem precisar reajustar todas as posições subsequentes.
A estrutura da árvore binária pode ser visualizada da seguinte forma:
_____ 1 ____
______/ \______
_ 01 _ 11
_/ \_ _/ \_
001 011 101 111
/ \ / \ / \ / \
0001 0011 0101 0111 1001 1011 1101 1111
No PostgreSQL, isso pode ser feito utilizando o tipo VARBIT, que permite a representação e manipulação de cadeias binárias variáveis. A ideia é gerar um novo VARBIT entre dois valores adjacentes para criar a nova posição.
CREATE TABLE card (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
position VARBIT UNIQUE
);
A função adj é responsável por criar uma nova posição ao ajustar a sequência de bits:
CREATE FUNCTION adj(orig VARBIT, b VARBIT) RETURNS VARBIT LANGUAGE SQL AS $$
SELECT substring(orig FOR LENGTH(orig)-1)
||b
||substring(orig FROM LENGTH(orig));
$$;
Já a função f define a lógica para determinar a nova posição entre dois valores adjacentes, considerando os casos em que um dos valores é NULL ou quando as sequências binárias têm comprimentos diferentes:
CREATE FUNCTION f(l VARBIT, h VARBIT) RETURNS VARBIT LANGUAGE plpgsql as $$
BEGIN
IF l IS NULL AND h IS NULL THEN RETURN B'1'; END IF;
IF l IS NULL THEN RETURN adj(h,B'0'); END IF;
IF h IS NULL THEN RETURN adj(l,B'1'); END IF;
IF LENGTH(l)>LENGTH(h) THEN RETURN adj(l,B'1'); END IF;
RETURN adj(h,B'0');
END;
$$;
Com isso, dado o meu exemplo anterior.
INSERT INTO card (content, position)
VALUES ('content1', B'001'),
('content2', B'011'),
('content3', B'101'),
('content4', B'111');
SELECT * FROM card ORDER BY POSITION;
| id | content | position |
|---|---|---|
| 1 | content1 | 001 |
| 2 | content2 | 011 |
| 3 | content3 | 101 |
| 4 | content4 | 111 |
Agora, se eu quero colocar o 3 na primeira posição, basta fazer a troca:
UPDATE card
SET position = f(null, B'001') -- entre null e 1
WHERE content = 'content3';
update card
set position = f(B'101', B'111') -- entre 3 e 4
where content = 'content1';
SELECT * FROM card ORDER BY POSITION;
| id | content | position |
|---|---|---|
| 3 | content3 | 0001 |
| 2 | content2 | 011 |
| 1 | content1 | 1101 |
| 4 | content4 | 111 |
O pior cenário dessa abordagem ocorre quando a lista é inicialmente carregada com muitas linhas já ordenadas. Isso pode levar a um problema de espaço, já que cada nova inserção exigirá um bit adicional na coluna position para acomodar a posição do novo item. Com o tempo, à medida que a lista cresce e mais posições intermediárias são inseridas, a position pode se tornar significativamente longa, consumindo mais espaço de armazenamento e potencialmente impactando o desempenho.
Conclusão
Neste post, exploramos várias abordagens interessantes para a ordenação de listas definida pelo usuário no banco de dados, começando por soluções simples e avançando para métodos mais sofisticados encontrados na literatura e na prática.
Sinseramente, a escolha da abordagem mais adequada depende das necessidades específicas do seu projeto. No entanto, espero que essa discussão tenha ajudado a esclarecer as diferentes opções disponíveis e como elas podem ser aplicadas para resolver problemas desse tipo de ordenação de forma eficiente.
Referências
Outra abordagem é usar Linked Lists criar referência do próximo e anterior para o item da lista, mas a consulta não é muito simples nesse caso.
Vi o título e a primeira coisa que passou na minha mente foi uma gambiarra que encontrei num sistema legado que dei manutenção certa vez:
Um campo string com os ids de cada um dos "cards", separados por vírgula.
Quando o "frontend" arrastava um dos cards para determinada posição, a string com a nova posição do card era atualizada. E essa string (que era armazenada num arquivo texto) poderia ser facilmente armazenada num campo texto de alguma tabela.
A complexidade foi levada para a view, etc, mas também é uma solução. rsrs