Node + Sequelize: Migração utilizando múltiplos bancos de dados

É muito comum em projetos de média e grande escala utilizarem mais de um banco de dados, múltiplos bancos tornam mais simples fazer backups (não é preciso se preocupar com dados de um cliente indo parar nos backups de outro) e talvez simplifique o crescimento em escala (dá para escalonar sistemas com banco único também — através de particionamento “vertical” ou “horizontal” — mas não tenho experiência prática suficiente para comentar).
Vou te mostrar como implementar as migrations para múltiplos bancos de dados, neste caso serão 2 banco de dados. Na documentação do Sequelize tem uma explicação clara de como fazer uma conexão com vários bancos dados, vamos pular essa parte, mas caso deseja ver como é feito, segue link de como é essa implementação: Documentação do sequelize ↗.
Diretório padrão: ./src/config/database.js
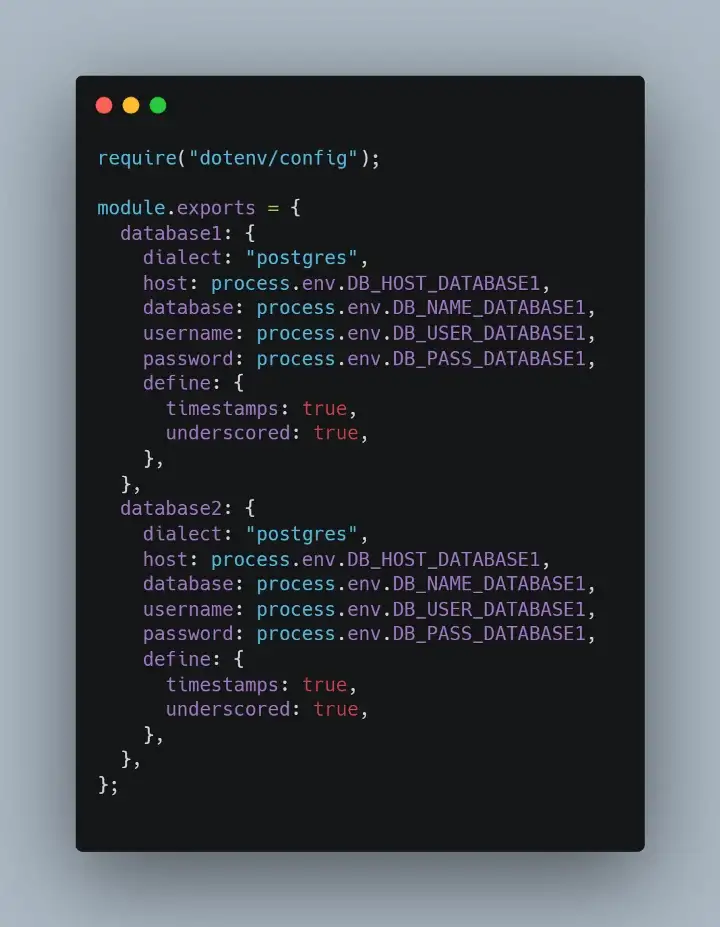
Não esqueça de colocar as credencias de acesso no .env, isso é uma boa prática.
Com o banco de dados já pronto para conexão, vamos agora dar início às configurações para poder criar as migrations para cada banco de dados. Vamos começar a configurar o .sequelizerc, que é o arquivo de CLI que define para onde vão as migrations e seeds que serão criadas.
Nesse nosso caso, vamos ter que criar dois desse arquivo de configuração um para cada banco de dados, os arquivos devem ser criados na raiz do projeto.
-
sequelize-database1
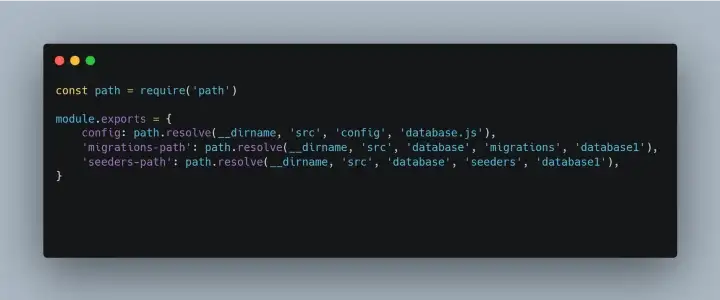
-
sequelize-database2 -
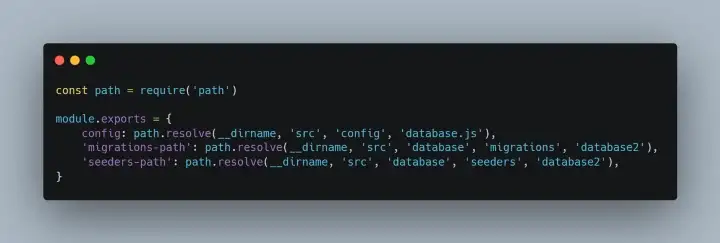
Com a configuração do CLI do sequlizer já criada e apontada corretamente, falta somente executar os comandos do sequlizer, certo !? Errado, por padrão qualquer comando do sequlizer, como o de criação do banco de dados — yarn sequelize db:migrate — vai está procurando por padrão o .sequelizerc e vai da erro.

E agora? O que podemos fazer ?! Não se preocupe, podemos modificar o comando do sequlizer especificando cada migrations e para isso vamos está alterando um pouco nosso arquivo package.json.
No arquivo package.json estaremos adicionando os comandos do sequelizer, com algumas alterações para apontar o arquivo correto conforme o banco de dados.
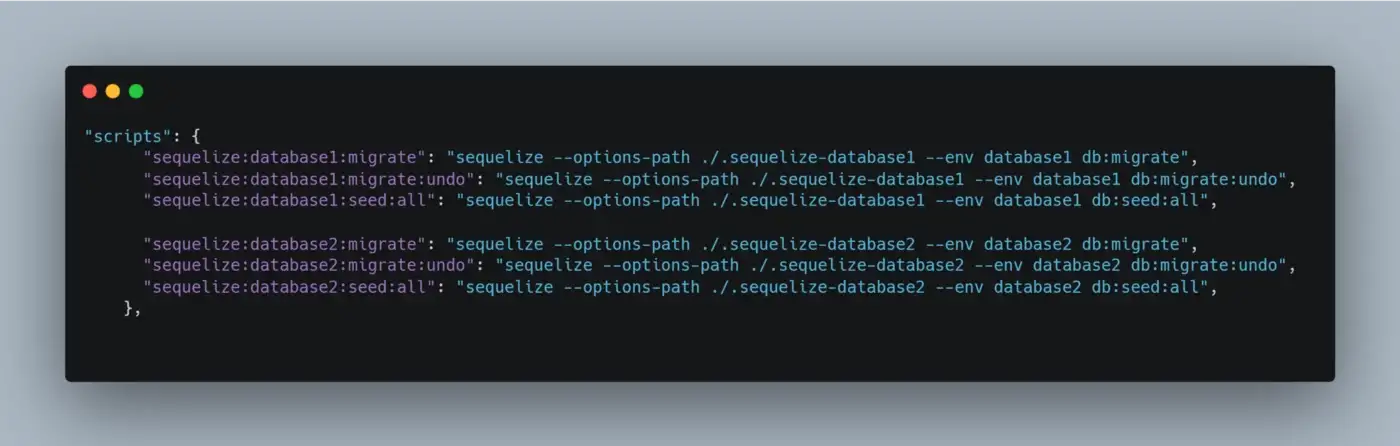
Com esses scripts adicionados podemos usar os dois arquivos do sequelizer (.sequelize-database1 ou .sequelize-database2) independente um do outro, podendo agora definir para qual banco de dados vai ser criado as migrations e seeds.
Ponderar executar o comando de criação de uma nova tabela para o banco de dados 2, sem interferir no banco 1, por exemplo:
yarn sequelize:database1:migrate - name=create-table-users
Ou atualizar os novos dados do banco 2, por exemplo
yarn sequelize:database2:seed:all
Espero que tenha gostado da explicação e que tenha ficado claro que como fazer o controle de múltiplos banco de dados usando as migration do sequelizer. Ficarei muito agradecido como qualquer tipo de feedback que acha interessante comentar, fique à vontade.
Referências
- https://sequelize.org/v6/
- https://pt.stackoverflow.com/questions/59401/usar-múltiplas-base-de-dados
- https://www.luiztools.com.br/post/tutorial-de-migrations-com-nodejs-e-sequelize/
- https://www.luiztools.com.br/post/tutorial-de-migrations-com-nodejs-e-sequelize/
- https://de.unetiq.com/blog-posts/using-multiple-databases-with-nodejs-and-sequelize
Apesar de já ter 3 meses a publicação, só encontrei agora e como estou estudando Nodejs achei muito relevante e interessante também, parabéns pelo Post!