River na Prática: Resolvendo um problema de classificação com Aprendizado de Máquina Online
Requisitos
Para seguir esse tutorial espera-se que você tenha conhecimento suficiente da linguagem de programação Python e da biblioteca Pandas e do uso de ferramentas como Google Colab ou Jupyter-notebook.
Ter lido os dois primeiros artigos da série de artigos sobre River que eu escrevi é desejável.
Instalação
A biblioteca River é feita para funcionar a partir do Python 3.8. A instalação pode ser feita usando o gerenciador de pacotes pip:
# Via notebook
!pip install river
# Via terminal
pip install river
Problema de Classificação
Nesse tutorial vamos explorar um problema de classificação usando o famoso dataset titanic.
Instale os três arquivos do dataset no link: https://www.kaggle.com/competitions/titanic/data
Adicione o dataset no seu workspace e vamos começar a trabalhar.
Preparação dos Dados
Com o seu notebook aberto, vamos ao código. Começamos criando um DataFrame pandas com os dados de treino e observando as cinco primeiras linhas.
import pandas as pd
dataframe = pd.read_csv('data/train.csv')
dataframe.head()
Isso deve mostrar o seguinte resultado:

Vamos nos concentrar em fazer um modelo simples. Nesse caso, as colunas que mais nos interessam são:
- Survived (Alvo): É uma coluna categórica com duas classes (1 para sobreviventes e 0 para não sobreviventes)
- Pclass: É uma coluna categórica com três classes (1 para primeira classe, 2 para segunda classe e 3 para terceira classe)
- Sex: Coluna categórica indicando o sexo do passageiro
Escolhi as features Pclass e Sex porque, historicamente, mulheres ricas foram as pessoas que mais sobreviveram.
Vamos filtrar essas colunas que são as únicas que nos interessam no momento
dataframe = dataframe[['Survived', 'Pclass', 'Sex']]
dataframe.head()
Mostrando o seguinte resultado:
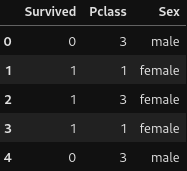
Agora vamos transformar a coluna Sex em uma coluna numérica (1 para male e 2 para female)
dataframe['Sex'] = dataframe['Sex'].replace({'male': 1, 'female': 2})
dataframe.head()
Obtendo como resultado:
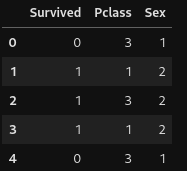
Por fim precisamos separar o dataset em features de treino e alvo (target). No nosso caso, Survived é o alvo e as demais colunas são as features de treino. Também irei transformar a coluna alvo de numérica para booleana para se adaptar ao modelo e a forma que o River trabalha.
features = dataframe[['Pclass', 'Sex']]
target = dataframe['Survived'].replace({0: False, 1: True})
Com todos nossos dados estando no formato desejado e separados em features e target, podemos começar a efetivamente trabalhar com o modelo.
Criação e treinamento do modelo online
O objetivo de um classificador é predizer qual a categoria de uma determinada amostra, predizer um alvo y para um conjunto de características x. Vamos fazer isso usando um modelo de regressão logística.
from river import linear_model
model = linear_model.LogisticRegression()
Com o código acima nós instanciamos o modelo.
Para treinar o modelo, basta alimentar ele com uma amostra dos dados por vez, mas como fazer isso se nossos dados são um grande lote? O módulo stream do River nos ajuda a lidar com isso e tem uma função chamada iter_pandas, que nos permite iterar um dataframe ou uma série pandas como se os dados estivessem chegando para nós em stream.
Experimente:
from river import stream
for X, y in stream.iter_pandas(features, target):
print(X, y)
Cada print vai mostrar um dicionário com as features e um valor para cada uma delas e ao lado o valor do target para aquela amostra.
Mas o que queremos não é simplesmente ver as amostras e sim ensinar ao modelo a predizer se dada uma amostra um passageiro sobreviveu ou não.
Para isso, podemos usar o método learn_one(X, y). Entretanto, vamos criar um objeto iterável chamado “stream_dataset” ao invés de chamar a função iter_pandas diretamente no laço de repetição. A motivação para isso vai ficar mais clara futuramente.
from river import stream
stream_dataset = stream.iter_pandas(features, target)
for X, y in stream_dataset:
model.learn_one(X, y)
Como estamos em um ambiente de aprendizado, vamos usar o mesmo dataframe para testar o modelo. Para um primeiro teste, vamos tentar predizer a primeira amostra do dataframe (homem que estava na terceira classe do navio e que não sobreviveu).
stream_dataset = stream.iter_pandas(features, target)
x, y = next(stream_dataset)
model.predict_one(x)
O resultado do código acima deve ser false pois de fato esse passageiro não sobreviveu.
Verificar o que o modelo prediz uma amostra de cada vez não é uma boa estratégia, então vamos avaliar o modelo de uma forma bem comum para iniciantes em aprendizado de máquina: armazenando a predição do modelo para cada iteração e verificar a classe real para aquela amostra e depois calcular uma certa “acurácia” para essas predições.
from river import metrics
metric = metrics.ROCAUC(n_thresholds=20)
stream_dataset = stream.iter_pandas(features, target)
for X, y in stream_dataset:
y_pred = model.predict_proba_one(X)
model.learn_one(X, y)
metric.update(y, y_pred)
metric
O resultado do código acima deve retornar algo por volta de 81%, o que não é um valor a se jogar fora. Mas vamos experimentar uma outra abordagem, mais próxima do padrão de treinamento e de validação do River.
A biblioteca River permite criar um modelo como uma Pipeline, ou seja, um processo de passos para o treinamento. Isso é feito simplesmente adicionando “|” entre os processos desejados.
Além disso, como dito no artigo de introdução do River, o aprendizado e a inferência acontecem na mesma ordem que acontece no ambiente de produção e para isso a biblioteca usa a função progressive_val_score, que recebe o dataset em formato de stream, o modelo e a métrica usada.
from river import evaluate
from river import optim
from river import preprocessing
from river import compose
stream_dataset = stream.iter_pandas(features, target)
model = (
preprocessing.StandardScaler() |
linear_model.LogisticRegression(optimizer=optim.SGD(.1))
)
metric = metrics.ROCAUC(n_thresholds=20)
evaluate.progressive_val_score(stream_dataset, model, metric)
Para otimizar o modelo, antes de os dados alimentarem o modelo, eles são redimensionados com o StandardScaler(). O modelo recebe um otimizador do tipo SGD para descida de gradiente estocástica simples. Por fim avaliamos o modelo com progressive_val_score.
O resultado retornado pela função na última linha deve ser por volta de 82%. Uma melhora não tão considerável em comparação à nossa versão anterior, mas uma melhora é uma melhora.
Por fim, caso você queira identificar com mais facilidade os elementos do seu pipeline do modelo, basta digitar model em uma célula do seu notebook e ver a imagem que define o pipeline. No nosso caso, por exemplo, temos:

Conclusão
Com esse artigo você é capaz de experimentar várias das formas de trabalhar com a biblioteca River para treinar e avaliar modelos de aprendizado de máquina online. Você limpou um conjunto de dados e aprendeu desde como lidar com dados em lote para que funcionem como dados em streaming até como construir e avaliar um modelo de aprendizado online.
Se esse conteúdo foi do seu interesse, não esqueça de avaliá-lo de alguma forma e de me seguir para acompanhar os próximos artigos.
Dúvidas, sugestões ou correções são muito bem-vindas na seção de comentários abaixo. Até a próxima.
Bom dia NobreLucas,
Uma dúvida sincera, qual é a diferença para o sklearn?
A minha pergunta é porque eu não consegui ver uma grande diferença e acho que muitas outras bibliotecas explicativas de modelos usam o sklearn como base.