O que é RAG? A técnica inovadora que está transformando os modelos de linguagem
"Nota do Autor: Saudações a todos! Atualmente, estou envolvido em um projeto emocionante com uma empresa que tem parcerias estratégicas com líderes de mercado, incluindo a Nvidia. Além disso, tenho planos de redigir um artigo abordando a indústria de hardware de alto desempenho no futuro próximo. Uma das minhas responsabilidades nesse projeto é desenvolver uma inteligência artificial para auxiliar nossa equipe interna no entendimento e aplicação das políticas e normas da empresa, além de aprender e contribuir com os procedimentos internacionais. O propósito deste artigo é compartilhar minhas pesquisas recentes, visando aprimorar o modelo de linguagem natural que estamos desenvolvendo, e também discutir, de forma teórica, uma tecnologia que está sendo amplamente adotada por gigantes como OpenAI, Microsoft e Tesla
O que é RAG?
O RAG, ou Retrieval-Augmented Generation, em um nível simples, é um modelo de recuperação de informações que visa aumentar a precisão nas respostas com base em um domínio específico. Por exemplo, ao utilizar a API do chat GPT para treinar um modelo que obtenha informações constantemente atualizadas, o RAG pode ser uma solução. Ele opera como um mecanismo que busca dados em uma reserva de conhecimento - similar a uma vasta biblioteca digital - para oferecer respostas ou atender solicitações específicas. O RAG funciona em três etapas simples:
- Recuperação: Nesta etapa, o RAG examina uma base de conhecimento ou domínio específico, podendo até mesmo acessar fontes externas, como páginas na Wikipedia, por exemplo.
- Análise do Prompt: Aqui, é feita uma análise do texto inicial inserido pelo usuário para compreender melhor sua intenção.
- Geração: Por fim, são geradas informações detalhadas com base nas etapas anteriores e no contexto fornecido pelo usuário.
Essencialmente, o RAG integra um mecanismo de busca com capacidades de geração de texto para fornecer respostas mais precisas e relevantes em contextos específicos.
Banco de dados vetorial: A chave para recuperação dos dados com eficiência
Os bancos de dados de vetores geralmente são usados para potencializar casos de uso de pesquisa de vetores, como pesquisa visual, semântica e multimodal. Mais recentemente, eles foram combinados com modelos de texto de inteligência artificial (IA) generativa para criar agentes inteligentes que fornecem experiências de pesquisa de conversação. Eles também podem evitar que modelos generativos de IA tenham alucinações, o que pode fazer com que os chatbots forneçam respostas não factuais, mas confiáveis.
O banco de dados vetorial é crucial entre esses componentes, fornecendo suporte crítico para os vários casos de uso. s pesquisadores rapidamente se viram limitados quando tentaram capturar as complexas relações e significados dos dados. Como explicar que "futebol" e "basquete" são ambos esportes, mas são distintos entre si? Ou ainda, como demonstrar que "vermelho" e "azul" são cores, mas não compartilham a mesma tonalidade? A abordagem de adicionar novas dimensões para cada nova categoria logo se mostrou inviável devido à sua complexidade crescente.
A solução veio na forma de vetores densos, onde cada conceito, como "esporte", "cor" ou "sentimento", seria representado por um vetor único com múltiplos valores distintos, ou seja, atributos. Por exemplo, em vez de [1, 0, 0] para "futebol", o vetor poderia ser [0.8, 0.6, -0.2, ...], capturando uma ampla gama de características do conceito. No entanto, criar manualmente esses vetores densos para todas as categorias possíveis era impraticável devido à sua diversidade e complexidade.
Além disso, esses vetores densos inicialmente não tinham um significado claro. Embora a máquina pudesse distinguir entre diferentes conceitos, como ensiná-la que "futebol" e "basquete" são mais semelhantes do que "futebol" e "bola de tênis"? A aplicação de noções de similaridade entre conceitos é fundamental para a compreensão do nosso mundo.
A nível de exemplo vou fornecer um código javascript executando uma query do LanceDB: O LanceDB é banco de dados vetorial de código aberto com fácil instalação e configuração.
// Embedded in your app, no servers to manage!
const lancedb = require("vectordb");
// Persist your embeddings, metadata, text, images, video, audio & more
const db = await lancedb.connect("./data/my_db");
const table = await db.openTable("my_table");
// Production-ready, scalable vector search with optional SQL filters
const query = await table.search([0.1, 0.3, 0.2])
.where("item != 'item foo'")
.limit(2)
.execute();
Este código em JavaScript usa a biblioteca vectordb para interagir com um banco de dados de embeddings vetoriais. Inicialmente, ele se conecta ao banco de dados localizado em "./data/my_db" e abre uma tabela chamada "my_table" dentro desse banco de dados. Essa tabela pode conter uma variedade de dados associados a embeddings vetoriais, metadados, texto, imagens, vídeos, áudio, entre outros.
Em seguida, o código realiza uma pesquisa na tabela utilizando um vetor específico [0.1, 0.3, 0.2], que provavelmente representa um embedding vetorial de algum tipo de dado. Além disso, ele aplica filtros opcionais usando uma sintaxe semelhante a SQL, onde ele exclui os resultados onde o valor da coluna "item" é igual a "item foo".
Alguns Casos de Uso interessantes
RAG tem muitas aplicações no ambito empresarial e de pesquisas, irei citar alguns do quais pesquisei e achei bastante útil a aplicação.
Usando RAG para atualizações em repositórios
Alice é uma desenvolvedora que deseja aprender sobre mudanças específicas em um repositório do GitHub (neste caso, o repositório do TimescaleDB). Em vez de inspecionar manualmente o código ou o histórico de commits, ela encontra um aplicativo chamado "Conversa com meu repositório do GitHub" e o utiliza para agilizar sua pesquisa. Alice quer saber sobre as mudanças recentes em um recurso chamado "agregados contínuos" e faz a seguinte pergunta em 29 de novembro de 2023:
O que há de novo com o recurso de agregados contínuos nos últimos 6 meses?
Resposta do LLM sem RAG consciente do tempo 👎
O recurso chamado agregados contínuos passou por algumas mudanças. A mudança mais recente foi feita por Sven Klemm em 24 de janeiro de 2020. Essa mudança adicionou um novo modo chamado agregados em tempo real, que combina dados materializados com novos dados recebidos após a última atualização. Esse novo modo é agora o comportamento padrão para agregados contínuos recém-criados. Para atualizar agregados contínuos existentes para o novo comportamento, um comando específico precisa ser executado.
Resposta do LLM com RAG consciente do tempo ✅
Nos últimos 6 meses, foram feitas duas mudanças no recurso chamado agregados contínuos. A primeira mudança foi feita em 7 de agosto de 2023, por Fabrízio de Royes Mello. Essa mudança relaxou o bloqueio forte da tabela ao atualizar um agregado contínuo, permitindo que o procedimento de atualização seja executado em várias sessões com menos bloqueios. A segunda mudança foi feita em 29 de agosto de 2023, por Jan Nidzwetzki. Essa mudança tornou o teste de atualização/downgrade determinístico, adicionando uma especificação ORDER BY a duas consultas em post.continuous_aggs.v3.sql.
A resposta usando RAG consciente do tempo é muito mais útil — está dentro do período de tempo especificado por Alice e é relevante para o tópico. A diferença entre as duas respostas está na etapa de recuperação.
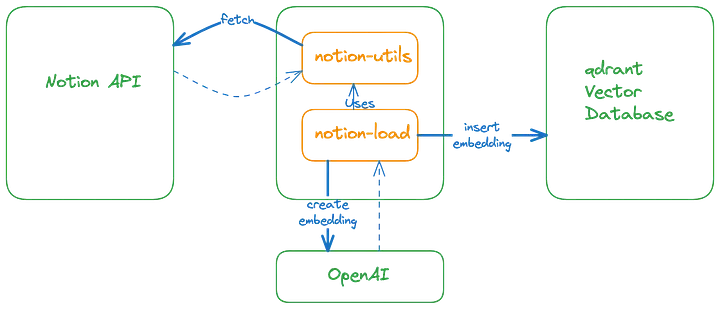
RAG + NOTION
Supondo que a base de dados de uma empresa não seja algo armazenada em um banco de dados ou alguma outra tecnologia que necesscite de codificação, mas simples algo mais simples de utilizar como Notion ou Google Docs. É possível fazer a integração com informações oriundas de outras aplicações, achei um artigo bem interessante no Medium que trata dessa questão
Conclusões e Referências
Bom, é isso pessoal. Ainda estou na parte de testar tecnologias relacionadas a inteligência artificial para que possa de fato implementar em código onde trabalho. IA no geral, algumas empresas andam se decepcionando bastante com a utilização das inteligências artificiais. Creio que isso seja comum, para qualquer inovação que entra no mercado! Na verdade, a inteligência artifical segue o ciclo hype de gartner.
Mas sendo honesto, estou bastante animado para as coisas que veremos nos próximos anos :D
Muito bom ,espero que um tutorial do LanceDB com mais funcionalidades seja brevemente também lançado.