🧭 Uma bússola dentro do Git: `HEAD`
Entendendo o HEAD 🧭
Vou representar Git como um conjunto de nós que apontam uns para os outros, assim a explicação fica mais simples. Esses nós seriam os commits (Figura 1).
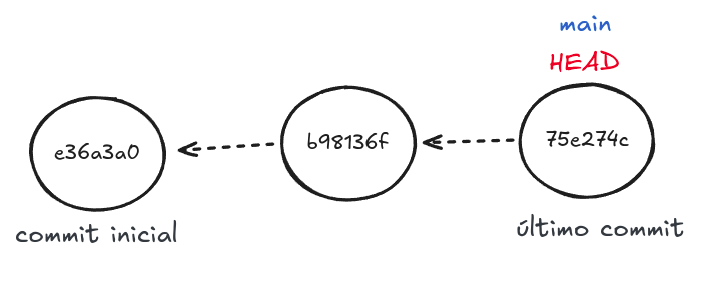
Figura 1 - Árvore de 3 commits
O HEAD é simplesmente uma referência, um ponteiro, para um commit (geralmente o último feito, na Figura 1 é 75e274c).
Quando o commit para o qual ele aponta não é o atual (isto é, NÃO É o último commit feito, NÃO é o topo do branch) isso se chama detached HEAD (ou HEAD desacoplado, Figura 2).
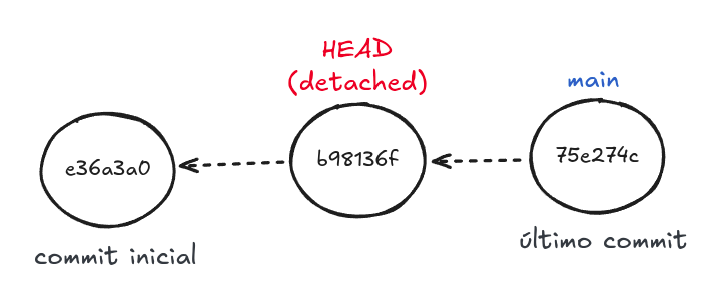
Figura 2 - HEAD detached
Por ser possível "desacoplar", nós podemos movimentar o HEAD para qualquer commit que a gente consiga identificar. Dois comandos que permitem fazer essa movimentação são:
git checkout <commit-hash>git switch -d <commit-hash>
Em resumo, o HEAD fornece uma abstração, um nome, para um commit e permite fazer movimentações e operações com ele de forma mais fluida.
🔎 Verificando para onde HEAD aponta
Tá. Eu entendi o que é o HEAD, mas como eu vejo para onde ele está apontando?
Bem, isso é possível por meio de vários comandos, entre eles:
git log -1(que mostra somente para onde HEAD aponta)git refloggit show HEAD
Que resultam em representações semelhantes a
941fb2b (HEAD -> main, origin/main) adiciona a feature
Nessa mensagem é possível ver HEAD -> main (HEAD aponta para main, que é uma branch).
Pode parecer estranho que, quando defini HEAD, não falei direito sobre branches e HEAD tá apontando para uma agora.
Long-story short (já que o escopo do post não é sobre branchs): branches também são ponteiros e também apontam para commits. Então HEAD apontar para main é o mesmo que apontar para o commit que main aponta.
Dentro do .git
Também dá para ver o HEAD acessando o diretório .git e acesando o arquivo de nome HEAD.
cat .git/HEAD -> ref: refs/heads/main
Ele aponta para main que é uma branch. Para ver para onde main aponta, fazemos
cat .git/refs/heads/main -> 75e274cf0ecdb3141e447d21e987a510b6f47f0b
Pronto: main aponta para um commit, logo HEAD aponta para um commit quando aponta para main.
Se o HEAD estiver detached ele vai apontar diretamente para o commit
cat .git/HEAD -> 75e274cf0ecdb3141e447d21e987a510b6f47f0b
🗺 Usando HEAD^ e HEAD~n para voltar no tempo
Agora, HEAD^ e HEAD~n. Esses operadores podem ser usados em branches e commits também, mas eu vejo muito mais casos em que eles vêm acompanhando o HEAD.
O HEAD^ faz referencia ao commit pai do HEAD (ou seja, o commit que vem antes). Voltando à Figura 1, o commit pai de 75e274c é o b98136f. Veja a Figura 3:
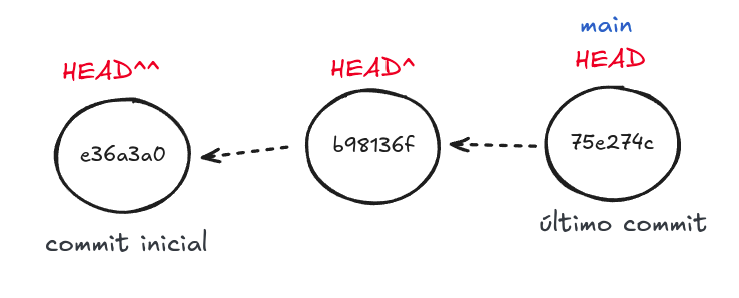
Figura 3 - HEAD^ e HEAD^^
Só que ficar usando vários ^ em sequencia fica inconveniente bem rápido. Para voltar um número maior de commits, temos o HEAD~n.
Nesse operador, n é o número de commits que você quer voltar (HEAD^ e HEAD~1 são equivalentes).
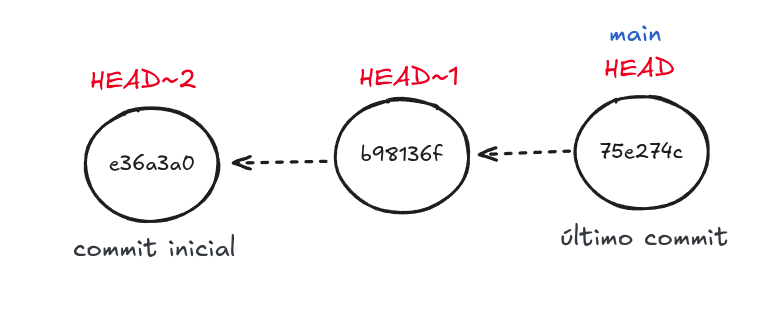
Figura 4 - Voltando commits com HEAD~n
Ambos são muitos úteis quando precisamos voltar nos commits, por exemplo em um git reset HEAD~3.
Basicamente é isso. Não é muito, e nem perto de ser tudo, mas é um pouquinho de algo muito interessante e que ajuda a ter uma experiência melhor com o Git que é uma ferramenta incrível.
Complementando, já escrevi um post mais detalhado sobre o assunto:
E aproveitando, seguem outros posts que escrevi sobre o Git (e que de certa forma complementam o primeiro, já que te dão uma visão mais clara e ampla sobre como funciona um repositório do Git):
- (Git internals) Como o Git grava os conjuntos de modificações do repositório?
- Você conhece os comandos switch e restore?
- Qual a diferença entre as opções "--soft", "--mixed e "--hard" no git reset?
- É possível commitar apenas parte das alterações?
Por fim, tem também este comentário sobre reflog, esta sim a verdadeira "máquina do tempo" do Git :-)
Apenas complementando sobre HEAD^ e HEAD~. É verdade que HEAD^^ é equivalente a HEAD~2, mas na verdade existe uma diferença mais fundamental sobre o funcionamento deles.
Para explicar a diferença, temos que lembrar que um commit pode ter mais de um pai, quando este é o resultado de um merge que não teve fast-forward.
O mais comum é quando eu faço git merge branch e não há fast-forward, pois aí o resultado é um commit com dois pais: o commit para onde o HEAD apontava e o commit para onde o branch aponta. Mas nada impede que eu faça algo como git merge branch1 branch2 branch3, e neste caso o commit resultante poderá ter até quatro pais (caso não seja possível fazer fast-forward em nenhum dos branches).
E é aí que usar ^ ou ~ começa a fazer diferença. Pois o ^N é usado para obter o enésimo pai, enquanto que ~N é usado para o enésimo ancestral.
Para entender melhor, segue um exemplo retirado da documentação oficial:
G H I J
\ / \ /
D E F
\ | / \
\ | / |
\|/ |
B C
\ /
\ /
A
No caso, o commit A tem dois pais: B e C. O commit B tem 3 pais: D, E e F, e assim por diante.
Se eu fizer A^, A^1 ou A~1, o resultado é B. Agora, como eu chego em C a partir de A? Neste caso, eu uso A^2, ou seja, o "segundo pai de A".
Já se eu fizer A~2 ou A^^ (ou ainda A^1^1), eu chego em D. E para chegar em E, tenho que fazer algo como B^2 (o segundo pai de B), ou ainda A^^2 (pois A^ equivale a B, e depois com ^2 eu chego em E).
Essa é a diferença: A^2 é o segundo pai de A, enquanto A~2 é o ancestral de A "voltando duas gerações" (e considerando sempre o primeiro pai de cada geração).
Ainda usando o mesmo exemplo: para chegar em F, podemos fazer B^3 (o terceiro pai de B), ou A^^3 (o terceiro pai do primeiro pai de A). Para chegar em H, posso fazer algo como A~2^2 (pois com A~2 eu chego em D, e depois ^2 pega o segundo pai de D, que é H).
Enfim, esses atalhos existem porque fazem coisas diferentes: ^ olha apenas uma geração acima, e procura pelo enésimo pai (ou o primeiro, se nenhum número for especificado). Já o ~ vai subindo na "árvore genealógica", podendo olhar várias gerações anteriores.
O fato de A^^ ser equivalente a A~2 é mera consequência desta definição. Mas o intuito original não foi um ser atalho para o outro.